
AWSはクラウドインフラにおいて、グローバル市場のトップシェアを誇るサービスです。そのAWSを利用するうえで、S3は欠かせないサービスの一つといえます。「AWSで自社インフラを構築したい」けれども、「S3がどのようなものかよくわからない」という方も多いのではないでしょうか。
そこでこの記事では、初心者向けにS3の概要や特徴とその利用方法、料金体系、他のサービスとの連携方法、そしてS3を活用したシステム設計のポイントについて解説します。
AWS S3とは?特徴とメリット
Amazonが提供しているAWS S3(Simple Storage Service)は、信頼性や柔軟性が高いクラウドストレージサービスです。S3はデータの保存・保管、アーカイブ、バックアップなど、さまざまな用途で利用可能な優れた特徴とメリットを持っています。
社内インフラの構築を考えている方にとって、S3の基本的な知識を理解することは非常に重要です。ここでは、S3の主要な特徴とメリットについて説明します。
容量無制限のオブジェクトストレージサービス
AWS S3は容量無制限のオブジェクトストレージサービスです。1つのオブジェクトあたり最大5TBまでのデータを格納可能で、保存可能なオブジェクト数は無制限です。S3ではデータをオブジェクトとして扱い、これらのオブジェクトはバケットと呼ばれるコンテナに保存されます。
各オブジェクトには一意の識別子キーを割り当て、体系的にデータを管理することができます。また、オブジェクトには任意のメタデータを付与できるため、大規模なデータセットの管理や急激に増加したデータの検索にも柔軟に対応することができます。
耐久性とセキュリティ性が高い
AWS S3は99.999999999%(イレブンナイン)の高い耐久性を持ち、複数のデータセンターへデータが自動的にコピーされます。そのため、自然災害やハードウェア障害などによるデータ損失のリスクを大幅に軽減することが可能です。
また、セキュリティ面では、強固な対策により不正アクセスを防止します。例としてデータの暗号化やアクセス制御、監査ログなどの機能がデフォルトで提供され、さらにAWS Identity and Access Management(IAM)を利用して、きめ細かなアクセス権限の管理が可能です。これらの機能により、重要なデータを安全に保管し、管理することができます。
スケーラビリティと柔軟性に優れる
データの増減に合わせて、自動的にスケール可能なことも特徴の一つです。ユーザーはデータ容量を事前に確保する必要がなく、必要に応じてストレージを自動的に拡張できます。この特性により、急激に保存データが増加しても適切に対応することが可能です。
また、S3はさまざまな用途に適用できる柔軟性も魅力の一つです。静的Webサイトのホスティング、大容量ファイルのアップロード、データバックアップ、長期データアーカイブなど、利用の用途は多岐にわたります。さらに、ほかのAWSサービスとの連携も容易で、システム全体における設計の幅を広げることができます。
バージョニングによるデータ保護と復元ができる
S3のバージョニング機能を利用すると、オブジェクトのバージョンを作成し、現行と過去のバージョンを保持できます。誤ってオブジェクトの削除や上書きをしてしまった場合でも、過去のバージョンからデータを復元することが可能です。
バージョニングを有効にすると、オブジェクトを更新するたびに新しいバージョンが作成され、古いバージョンも引き続き保持されます。この機能を使って、データの変更履歴を追跡したり、必要に応じて特定の時点のデータを参照したりすることも可能です。
また、バージョニングはデータ保護の観点からも重要で、悪意のあるデータの削除や改ざんからデータを守り、重要な情報の損失を防ぐことができます。
ライフサイクルポリシーによるコストの最適化
S3のライフサイクルポリシー機能を活用すると、データストレージの利用コストを最適化できます。ライフサイクルを設定して、オブジェクトを自動的に別のストレージクラスへ移行したり、削除したりすることにより、コストの最適化が実現可能です。
例えば、アクセス頻度の低いデータを標準ストレージクラスからS3 Glacier Deep Archiveなどの低コストストレージクラスに自動で移行させると、ストレージコストを大幅に削減できます。また、一定期間経過後にデータを自動削除するポリシーを設定すると、不要なデータの蓄積を防ぎ、ストレージ容量を効率的に利用できます。
ライフサイクルポリシーは、バケット単位やフォルダ単位で細かく設定することが可能なため、データの重要度や利用頻度に応じて柔軟な管理が実現可能です。
AWS S3の使い方とおもな利用方法
ここでは、S3の基本的な使い方とおもな利用方法について紹介します。これらの知識は、AWSで社内インフラなどを構築する際に役立つでしょう。
バケットの作成とオブジェクトのアップロード
S3は、バケットと呼ばれるコンテナを作成し、そこにオブジェクト(ファイル)をアップロードすることが基本的な使い方です。バケットを作成する際は、リージョンを選択し、適切なアクセス権限を設定することが重要です。
なおリージョンについては、わかりやすく解説した記事「AWS リージョンとは?わかりやすく解説」こちらも合わせてご確認ください。
オブジェクトのアップロードには、AWS Management Console、AWS Command Line Interface(AWS CLI)、AWS SDKなどを使用します。また、バケットポリシーやアクセスコントロールリスト(ACL)を使用して、きめ細かなアクセス制御を行なうことも可能です。
静的Webサイトのホスティング
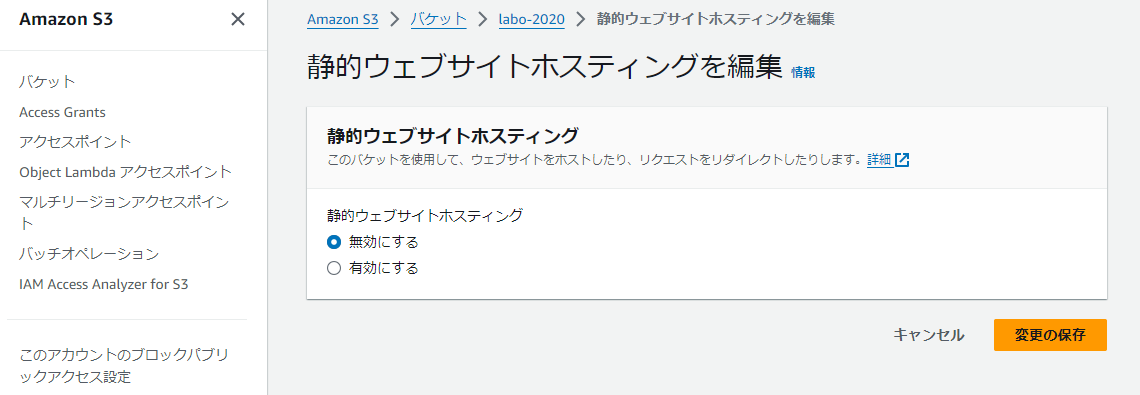
ここからは代表的なS3の利用方法についていくつか解説します。
1つ目の利用方法は、静的Webサイトのホスティングです。HTMLファイル、CSSファイル、JavaScriptファイル、画像ファイルなどといった静的コンテンツをS3バケットにアップロードし、静的Webサイトホスティング機能を有効にするだけで、Webサイトとして公開できます。
S3による静的Webサイトのホスティングは、サーバーの管理が不要で、高い可用性と耐久性を持つため、コスト効率の良いソリューションとなります。
データレイクとビッグデータ分析基盤
データレイクとは、すべての構造化データと非構造化データを、そのまま保存可能な一元化されたリポジトリのことです。S3の無制限に近いデータ容量、高い耐久性、低コストといった特性は、データレイクの要件を満たします。
S3をデータレイクとして使用すると、異なる種類のデータを一箇所に集約し、必要に応じてデータ構造の定義や分析を適用することができます。AWSの分析サービスと連携することで、強力なビッグデータ分析基盤を構築することが可能です。
バックアップとリストア
AWS Backupと連携することにより、簡単にバックアップ・リストア環境を構築できます。また、S3の高い耐久性と可用性により、データの安全性を大幅に向上させることが可能です。
バックアップ方法としては、他のAWSサービス(EC2、RDS、EBSなど)からS3にデータをバックアップする方法や、オンプレミスのデータをS3にバックアップする方法があります。リストアの際は、AWS BackupコンソールやAWS Backup APIなどを使用して、必要なデータを簡単に復元できます。
S3を災害復旧(DR)計画の一部として活用し、ビジネスの継続性を確保することに利用することも可能です。
低コストのデータアーカイブ
S3には複数のストレージクラスがあり、データのアクセス頻度や重要度に応じて最適なクラスを選択することによって、コストを最適化できます。さらに、S3のライフサイクルポリシーを設定することで、データの経過時間に応じて自動的にストレージクラスを変更したり、不要になったデータを自動削除したりできます。
この特性を活かして、データの重要度や利用頻度に応じた最適なストレージ管理を実現できるでしょう。データレイクのような使い方から低コストのデータアーカイブまで、幅広く対応することが可能です。
AWS S3の料金体系と無料利用枠
AWSの料金体系は「ストレージクラス」「データ転送量」「リクエスト量」の3つの要素から構成されています。それぞれ料金体系を理解するうえで欠かせない要素であるため、個別に説明します。また、無料利用枠についても併せて解説します。
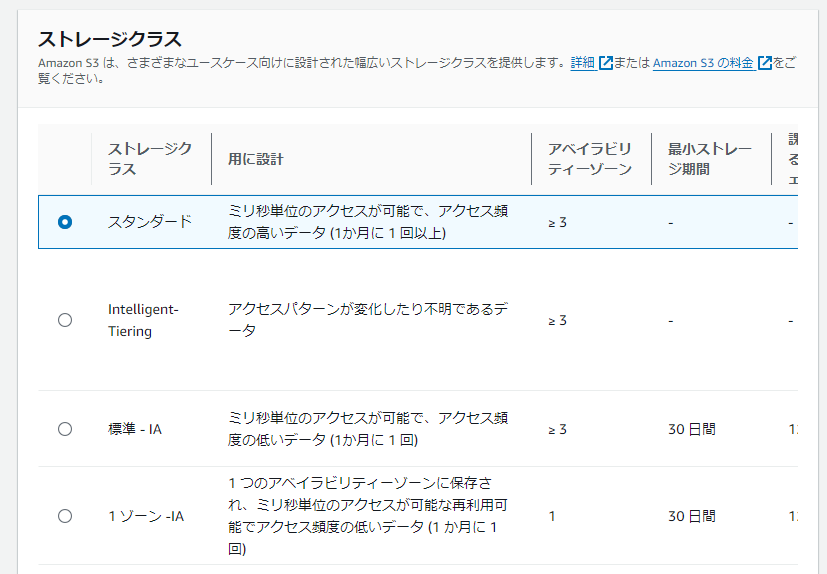
ストレージクラス
S3のストレージクラスは、データの保存方法と取り出し頻度に応じて選択できる料金体系です。どのクラスもアップロードしたデータ量に応じて課金されますが、用途に合わせて最適なクラスを選ぶことでコストを抑えることができます。
- S3 Standard:頻繁にアクセスするデータ向け
- S3 Intelligent-Tiering:アクセスパターンが不明または変化するデータ向け
- S3 Standard-IA:アクセス頻度は低いが即時取り出しが必要なデータ向け
- S3 One Zone-IA:重要度が低く、アクセス頻度も低いデータ向け
- S3 Glacier Instant Retrieval:即時取り出しが必要なアーカイブデータ向け
- S3 Glacier Flexible Retrieval:取り出しに1分~12時間かかる、アーカイブデータ向け
- S3 Glacier Deep Archive:年に1〜2回程度しかアクセスしない長期保存データ向け
これらのクラスを適切に選択することで、データの特性に応じたコストの最適化が可能となります。
データ転送量
データ転送量は、S3内のデータをダウンロードしたり、他のAWSサービスやインターネットに転送したりする際に発生する料金です。データをS3にアップロードする際には料金はかかりません。同一リージョン内でのデータ転送は無料ですが、リージョンをまたぐ転送やインターネット経由の転送には料金が発生します。
例えば、S3からEC2インスタンス(EC2上で稼働するサーバー)へのデータ転送は同一リージョン内であれば無料ですが、異なるリージョンのEC2インスタンスへ転送する場合には料金がかかります。システム設計の際にはデータの配置とアクセスパターンを考慮し、不要な転送を最小限に抑えることが重要です。
リクエスト量
S3へのアクセスに応じて課金されるものがリクエスト量です。GET、PUT、COPY、POSTなどの各種リクエストに対して単価が設定されており、それらの使用量に応じて課金されます。例えば、オブジェクトの取得(GET)、アップロード(PUT)、コピー(COPY)などの操作ごとに料金が発生します。
ただし、一部のエラーレスポンスに対しては請求対象外です。リクエスト量の料金は、ストレージやデータ転送量と比べると比較的小さいものですが、大量のリクエストを行なう場合には無視できない金額になる可能性があります。そのため、アプリケーションの設計時には不要なリクエストを減らすことや、バッチ処理を活用してリクエスト数を最適化することが重要です。
12ヵ月間無料利用枠あり
AWSには新規ユーザー向けに3種類の無料利用枠が用意されており、S3は12ヵ月間無料利用枠の対象となっています。この無料枠では、5GBの標準ストレージ、20,000件のGETリクエスト、2,000件のPUTリクエストが12ヵ月間無料で利用可能です。
これは、小規模なWebサイトのホスティングやアプリケーションの開発・テストには十分な量です。無料枠を活用することで、コストを気にせずS3の機能を試すことができ、本格的な利用を開始する前に使い方や性能の確認ができます。
ただし、無料枠の範囲を超えた利用や、無料枠の対象外となるサービスを使用した場合には通常の料金が発生するため、利用状況は定期的に確認するようにしましょう。
AWS S3とほかのAWSサービスとの連携例
AWS S3は単独でも強力なストレージサービスですが、ほかのAWSサービスと連携することでさらに多様な用途に活用できます。ここでは、S3とほかのAWSサービスを組み合わせることで実現できる機能や、システム設計のヒントとなる連携例についていくつか紹介します。
AWS Lambdaによるサーバーレスデータ処理
AWS LambdaとS3を連携することで、アップロードされたデータに対して自動的に処理を実行できます。例えば、S3にアップロードされた画像を自動的にリサイズしたり、動画を別のファイル形式や解像度に変換したりすることが可能です。S3のイベント通知機能を使用して、ファイルがアップロードされた際にLambda関数を呼び出すことで、これらの処理を完全にサーバーレスで実行できます。
また、大量のデータを並列処理することも可能なため、効率的なデータのパイプライン処理を構築することも可能です。AWS LambdaとS3の連携は、このようにメディアファイルの処理やアップロードされたファイルの検証、データ変換などさまざまなユースケースに適用できます。
Amazon CloudFrontによるコンテンツ配信の高速化
Amazon CloudFrontはAWSのCDN(Contents Delivery Network)サービスで、S3と組み合わせることでWebコンテンツの配信を大幅に高速化できます。例えば、S3にはWebサイトのアセット(画像、CSS、JavaScriptファイルなど)を保存しておきます。
CloudFrontを通じて配信することで、世界中のエッジロケーションのうちユーザーに最も近いサーバーからコンテンツを提供できるようになります。その結果、ページの読み込み時間が短縮され、ユーザーエクスペリエンスが向上する仕組みです。
また、CloudFrontはコンテンツをエッジロケーションにキャッシュするため、S3のオリジンに対する直接のアクセスが減少し、オリジンサーバーの負荷も軽減されます。
なお、エッジロケーションについては、こちらの記事も合わせてご確認ください。
「AWS エッジロケーションとは?わかりやすく解説」
AWS Snowballによる大容量データの移行
AWS Snowballは、ペタバイト規模の大容量データをAWSへ効率的に移行するためのデバイスとサービスです。S3との連携により、オンプレミスの大規模データセットをクラウドに移行する際の課題を解決します。
例えば、数十TBから数PB(ペタバイト)のデータをS3に移行する場合、通常のインターネット回線では過大な時間がかかるでしょう。また、帯域幅コストが高騰する問題もあります。Snowballを使用することにより、物理的にデータを転送し、その後S3にインポートすることが可能です。Snowballを活用してネットワークの制約を回避し、セキュアかつ高速なデータ移行が可能となります。
Amazon Athenaを使ったS3データの対話的分析
Amazon AthenaはS3に保存されたデータに対して、標準的なSQLを使用して直接クエリを実行できる、インタラクティブなクエリサービスです。S3とAthenaを組み合わせることで、複雑なインフラを構築することなく、大規模なデータセットをサーバーレスで分析できます。
例えば、S3に保存されたCSV、JSON、Parquetなどといった形式のログファイルやビジネスデータに対してSQLクエリを実行し、即座に結果を得ることができます。これは、ログ分析、アドホッククエリの実行、ビジネスインテリジェンスの導入など、さまざまなユースケースに適用可能です。Athenaはサーバーレスであるため、インフラの管理が不要で、実行したクエリに対してのみ課金されるため、コスト効率が高くなります。
Amazon SageMakerによる機械学習モデルの構築とデプロイ
Amazon SageMakerは、大規模な機械学習モデルの構築、トレーニング、デプロイを容易にする完全マネージド型のサービスです。S3と組み合わせることで、効率的な機械学習ワークフローを実現できます。具体的には、S3をデータレイクとして使用し、大量の学習データやテストデータを保存します。
SageMakerは、このS3上のデータを直接読み取り、モデルのトレーニングを実行することが可能です。また、トレーニング済みのモデルもS3に保存可能で、必要に応じて再利用や共有ができます。SageMakerとS3の連携によって、インフラの管理を気にすることなく、データサイエンティストはモデル開発に集中できるようになります。
AWS Lake Formationを使ってセキュアなデータレイク構築
AWS Lake Formationは、S3をベースにしたセキュアなデータレイク環境の構築と権限の一元管理を支援するサービスです。S3とLake Formationを組み合わせることで、数日から数週間でデータレイクを構築し、セキュリティやガバナンス、データ共有を簡単に管理できるようになります。Lake Formationは、S3バケットに保存されたデータに対して、きめ細かなアクセス制御を提供します。
例えば、特定のユーザーやグループに対して、特定のデータセットや行列レベルでアクセス権限を設定可能です。また、データカタログ機能を使用して、S3内のデータの構造や形式を自動的に検出し、メタデータを管理することができます。Lake Formationを活用することで大規模データの検索や分析が容易になり、データサイエンティストやアナリストの生産性が向上するでしょう。
AWS S3を活用したシステム設計のポイント
AWS S3を効果的に活用するためには、いくつかの重要なポイントを押さえておく必要があります。ここでは、S3を使ったシステム設計において覚えておきたい主要なポイントについて解説します。
データ整合性を保つためにチェックサムを用いる
S3にデータをアップロードする際、チェックサムを使用することでデータの整合性を確保できます。S3は、CRC32、CRC32C、SHA-1、SHA-256などのチェックサムアルゴリズムを利用可能です。チェックサムを利用することにより、データの転送中や保存中に発生する可能性のあるデータの破損や改ざんを検出することが可能です。チェックサムを用いることで、データの完全性を保証し、信頼性の高いストレージシステムを構築できます。
意図しないデータ公開を防ぐためのアクセス制御設定
S3のアクセス制御は、IAMポリシー、バケットポリシー、ACL(Access Control List)の3つの方法で管理します。IAMポリシーはユーザーやロールに対するアクセス制御を定義し、バケットポリシーはバケット単位でのアクセス制御を行ないます。ACLはオブジェクト単位での細かい制御が可能です。これらを適切に組み合わせることで、意図しないデータの公開を防ぎ、情報漏えいのリスクを最小限に抑えることが可能です。
大量データ転送時のネットワーク帯域の確保
S3とEC2インスタンス間のデータ転送速度は、理論上最大100Gbpsの帯域幅を利用できます。しかし、実際の転送速度はインスタンスタイプ、ネットワーク設定、S3バケットの設定などに依存します。そのため、大量のデータを効率的に転送するためには、これらの設定に対して最適化が必要です。
例えば、高性能なインスタンスタイプを選択し、拡張ネットワーキングを有効にすることで、ネットワークのスループットを向上させることができます。大規模なデータ移行や定期的な大容量バックアップなどを行なう際は、これらの点を考慮してシステムを設計することが重要です。
APIの呼び出し頻度に応じたアプリケーション設計
S3の料金体系はリクエスト数に応じて課金されるため、アプリケーションの設計時にはAPIの呼び出し頻度についても考慮しなければなりません。不要なリクエストを削減し、効率的なデータアクセスを行なうことでコストを最適化できます。
例えば、頻繁にアクセスされるオブジェクトをキャッシュしたり、バッチ処理を利用して複数のオペレーションをまとめて実行したりすることによって、リクエスト数を削減できます。
また、AWS Cost Explorerを使用して今後のコストを見積もり、コスト管理を行なうことも重要です。アプリケーションの設計段階からこれらの点を考慮することによって、長期的なコスト削減につながります。
クロスリージョンレプリケーションによる災害対策
S3のクロスリージョンレプリケーション機能を使用すると、異なるリージョンにデータを非同期的に複製できます。災害などによるリージョン単位の障害時にデータ損失を防ぎ、効果的な災害対策として利用することが可能です。ただし、レプリケーションにはコストがかかるため、重要なデータのみを選択してレプリケーションを設定するなど、コストとメリットのバランスを考慮する必要があります。
S3 Selectを使った効率的なデータ検索とフィルタリング
S3 Selectを使用すると、S3に保存されたCSVやJSON形式のデータに対してSQL風のクエリを実行できます。これにより大量のデータセットから特定のデータを効率的に検索・フィルタリングすることが可能です。
例えば、大規模なCSVファイルから特定の列のみを抽出したり、条件に合致する行だけを取得したりすることができます。S3 Selectを利用することにより、データ転送量を削減し、クエリのパフォーマンスを向上させられます。
なお、S3 SelectはAthenaと似た機能を持ちますが、Athenaがより複雑なクエリの実行や大規模なデータ分析に適しているのに対し、S3 Selectは単一のオブジェクトに対する簡単なクエリの実行に適しています。両者の違いについて理解したうえで使い分けるようにしましょう。
コスト管理のためのストレージクラス選択とライフサイクルポリシー
S3は用途に応じて複数のストレージクラスを提供しており、適切なクラスの選択により、コスト効率の高いストレージ設計が可能です。S3 Intelligent-Tieringを利用すれば、最適なストレージクラスへ自動的にデータを移動させることもできます。
また、ライフサイクル管理機能を活用することで、オブジェクトの経過時間に応じて自動的に異なるストレージクラスへ移行したり、不要になったオブジェクトを自動削除したりすることができます。
例えば、「アップロードから30日後にStandard-IAクラスに移行し、1年後にGlacierクラスに移行、3年後に削除」といったポリシーを設定することが可能です。これらの機能を適切に利用することにより、長期的なコスト管理を効率化できます。
S3 Intelligent-Tieringによる自動コスト最適化
S3 Intelligent-Tieringは、データのアクセスパターンを自動的に分析し、アクセスパターンに変化があれば最適なストレージクラスへオブジェクトを移動させます。これらによってS3のストレージコストを自動的に削減できるストレージクラスです。
S3 Intelligent-Tieringを利用すると、頻繁にアクセスされるデータや、アクセス頻度が低いデータを適切な階層へ自動的に保存するため、手動での管理が不要になります。特にアクセスパターンが予測困難なデータや、長期保存が必要なデータに対して効果的です。
まとめ
AWS S3は、高い耐久性と可用性を持つスケーラブルなクラウドストレージサービスです。容量無制限のオブジェクトストレージとして、さまざまな用途に利用できます。他のAWSサービスとの連携も容易で、Lambda、CloudFront、Athenaなどと組み合わせることによって、より高度なデータの処理や分析が実現できるようになるでしょう。
S3を利用する際には、この記事で解説した連携例やシステム設計のポイントなどについても参考にして、目的に応じて最適化してみてはいかがでしょうか。S3を上手に活用することができれば、柔軟で効率的なクラウドインフラの構築に役立てられるでしょう。
当記事の監修
GMOグローバルサイン・ホールディングス株式会社が運営するCloudCREW byGMOでご紹介する記事は、AWSなど主要クラウドの認定資格を有するエンジニアによって監修されています。